Two-Legged Spot: Teaching a Quadruped to Only Use Its Hind Legs for Locomotion
 Spot moving on its hind legs after 38,000 training iterations.
Spot moving on its hind legs after 38,000 training iterations.Spot is a quadruped robot built by Boston Dynamics, designed for stable four-legged locomotion across many terrains. In this project, I taught Spot how to stand and move on its hind legs.
The task is challenging for two reasons. First, balancing on two legs requires Spot to pitch its body backward by 50–80°, which is significantly different from its usual walking posture. Second, the default reward function used for quadruped locomotion actively penalizes the upright posture, because most of its terms assume four feet on the ground. The following sections detail how I overcame these challenges.
Table of Contents
The Simulation Stack: Isaac Lab and RSL-RL
Training a locomotion policy on real hardware is impractical. A single policy update requires thousands of environment interactions, each of which takes wall-clock time and risks mechanical damage. The standard approach is to train entirely in simulation and transfer the resulting policy to the real robot, a process known as sim-to-real transfer.
For this project, I used NVIDIA Isaac Lab, a GPU-accelerated robotics simulation framework built on top of PhysX. Because the physics simulation runs entirely on the GPU, Isaac Lab can run thousands of environments in parallel. I ran 8,192 copies of Spot at once. Each copy collected its own experience, and all copies fed the same policy update (Figure 1).

For the RL algorithm, I used Proximal Policy Optimization (PPO) from the RSL-RL library, developed at ETH Zürich’s Robotic Systems Lab for legged locomotion research. PPO is an on-policy actor-critic method: the policy (actor) proposes actions, and a value function (critic) estimates future returns. PPO updates both under a clipped objective that keeps each new policy close to the previous one, since large updates would otherwise destabilize training. Each PPO iteration collected a fresh batch of rollouts across all 8,192 environments. With num_steps_per_env=24, each batch contained roughly 196,000 transitions, over which PPO ran 5 optimization epochs before discarding the batch.
Getting Spot to Walk
Before teaching Spot anything new, I needed a baseline four-legged walking policy. Later runs would warm-start from this checkpoint rather than relearn locomotion from scratch. I trained the baseline using the default RSL-RL parameters.
Reward Design for Quadruped Locomotion
In Isaac Lab, the reward function specifies behavior entirely. It is a weighted sum of roughly 15 scalar terms evaluated every step. The policy never receives explicit instructions; it only sees observations and the scalar consequences of its actions. Designing the reward function is the central engineering task.
For quadruped locomotion, the reward terms split into two groups.
The first group, task rewards, encourages the behavior I want:
base_linear_velocityandbase_angular_velocityreward tracking the commanded velocity using exponential kernels ($r = e^{-\text{err}/\sigma}$, where $\text{err}$ is the velocity tracking error and $\sigma$ controls how quickly the reward falls off).air_timeshapes gait timing by rewarding each foot for spending roughly 0.3 seconds in the air or in contact per stride.foot_clearancerewards proper swing height.
The second group, regularization penalties, constrains the motion:
action_smoothnesspenalizes jerky control.joint_torquesandjoint_veldiscourage wasteful motion.foot_slippenalizes sliding contacts.base_motiondiscourages unnecessary vertical bouncing.
Training the Baseline Locomotion Policy
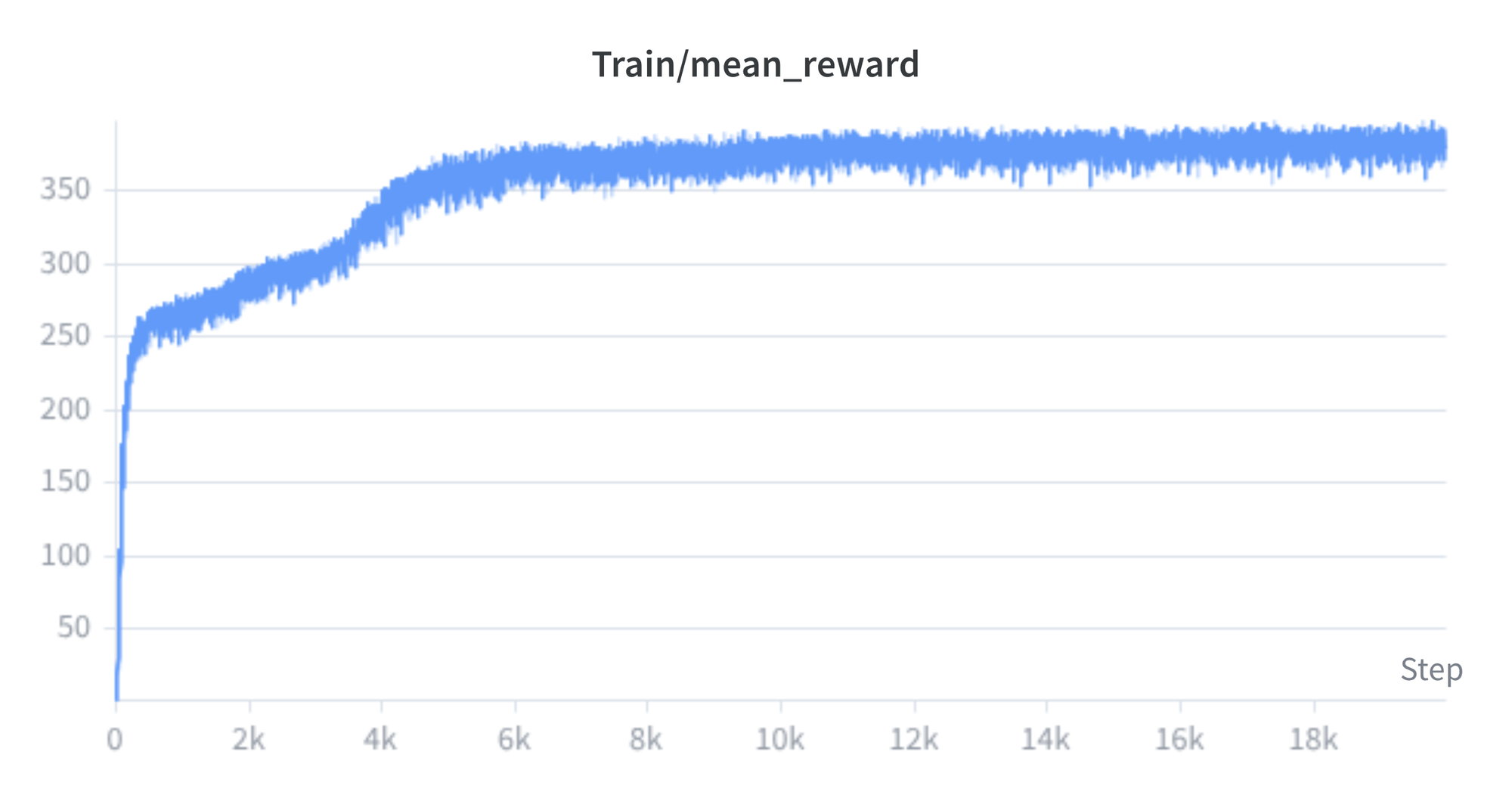
With this reward structure in place, I trained the policy from a random initialization. The progression is typical of locomotion RL. At iteration 0, the policy outputs random joint commands and Spot immediately falls (Figure 2). Within a few hundred iterations, the policy discovers that hopping earns local reward, but it has not yet found an efficient gait (Figure 3). By iteration 6,000, Spot walks cleanly and follows velocity commands in both directions (Figure 4). The reward curve in Figure 5 shows steady convergence to a mean episode reward near 380.



Nudging Spot Off Its Front Legs
With a quadruped walker as the starting point, I needed to push the policy toward bipedal behavior. I made two changes: a new reward term that penalizes the front feet for touching the ground, and a different distribution of training commands that emphasizes standing.
The Primary Shaping Signal: Front Feet Contact Penalty
The new reward term, front_feet_contact_penalty (weight −5.0), penalizes the robot for every timestep either front foot is in contact with the ground. A foot counts as in contact when the net force on it exceeds 1 N, measured from the contact force history buffer.
The weight of −5.0 is large compared to the rest of the reward function. The base_linear_velocity tracking reward, for comparison, tops out around +5.0; keeping both front feet down therefore costs more than the entire velocity tracking reward earns. Figures 6 and 7 show the early response: Spot begins pushing itself upright in brief attempts, but cannot yet sustain the posture.


Adjusting the Command Distribution
Alongside the penalty, I changed two things about how training commands were sampled.
First, I increased the standing fraction from its default to 80% (rel_standing_envs=0.8) and tightened the velocity range to ±0.15 m/s lateral and ±0.15 rad/s yaw. Balancing on two legs from a near-stationary position is a prerequisite for moving in that posture, so the policy needs more practice standing before it can walk bipedally.
Second, I disabled the GaitReward term (weight set to 0.0), which enforces a quadruped diagonal-pair gait. The diagonal-pair pattern is incompatible with bipedal locomotion.
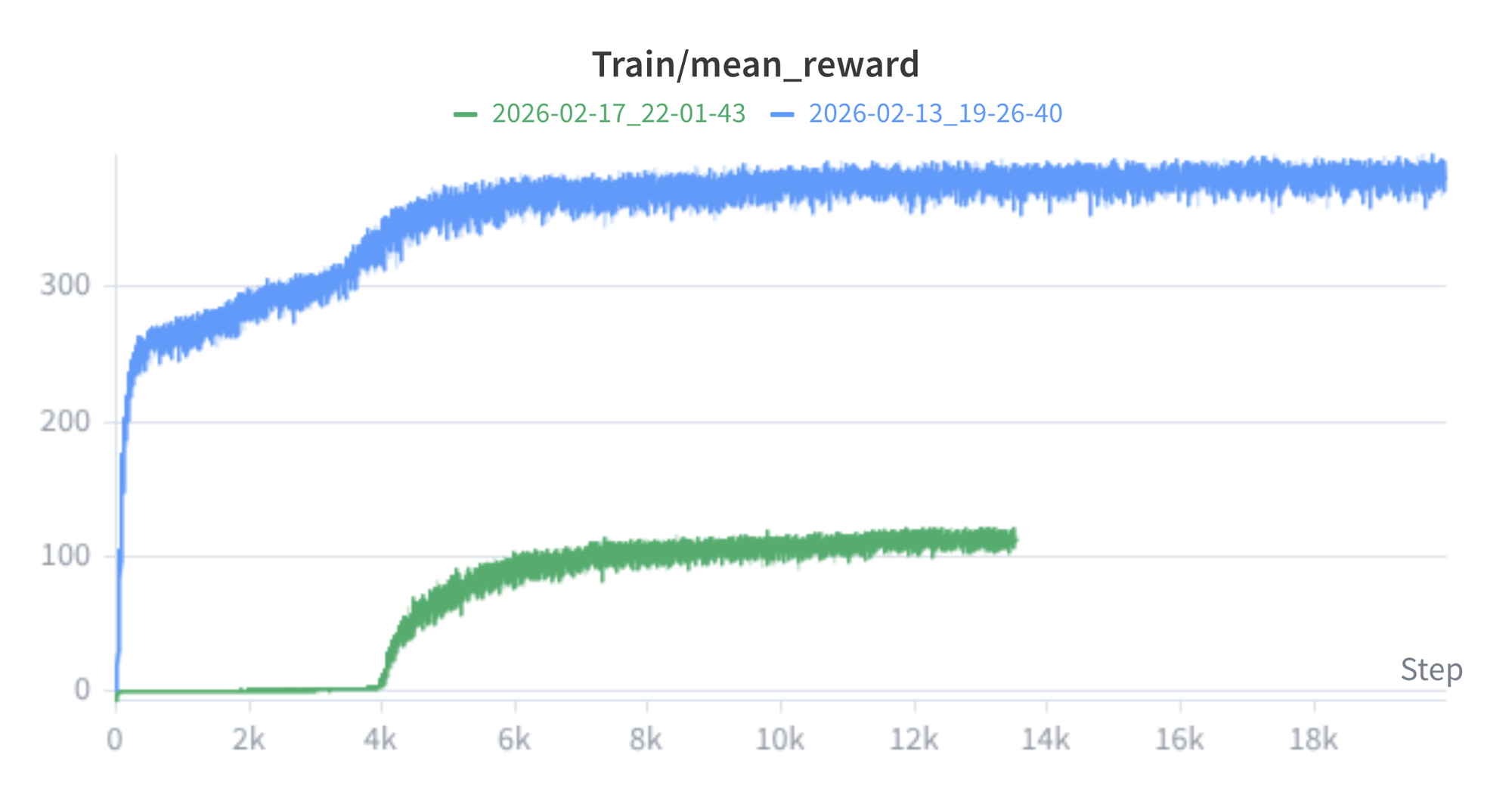
Figure 8 compares the reward curves of the quadruped run and the first hind legs run. The hind legs curve sits well below the quadruped baseline. Two effects explain the gap. The reward function itself changed (with GaitReward disabled and several other weights reduced or zeroed), and with 80% of environments commanding Spot to stand rather than move, the velocity tracking rewards fire much less often.
The Reward Engineering Gauntlet
The penalty was enough to lift Spot briefly, but not enough to make it stand. Each attempt ended the same way: a push up, a wobble, then a fall. The remaining work was figuring out what was blocking the transition from brief lift to sustained balance, and adjusting the reward function accordingly. This process took several iterations.
Training Instability in Early Runs
Early runs produced a policy that repeatedly faceplanted: Spot pushed its front feet off the ground, lost balance, and fell forward, with no lasting upright progress (Figure 9).

I do not have a definitive explanation for the failure. One might hypothesize that the heavy front feet penalty, combined with several conflicting regularization terms, made the reward landscape unstable and caused Spot to simply faceplant. The instability pointed to two next steps: add explicit safety penalties to discourage catastrophic falls, and audit the remaining reward terms for conflicts with the target posture.
Rewards That Were Fighting the Goal
Several of the existing regularization terms were actively penalizing the posture I wanted. Standing on two legs requires Spot to pitch its body backward by 50–80°, shift its center of mass over the hind feet, and hold the front legs elevated. All three are deviations from the default quadruped stance, and the original reward function penalized them.
The most significant conflicts and the changes I made:
base_orientation(weight −3.0): penalized the base frame for leaning away from gravity, using the projected gravity vector. Pitching back to stand upright is exactly that motion. I relaxed the term to penalize only roll (lateral tipping), leaving pitch unconstrained.base_motion(weight −2.0): penalized vertical velocity and roll/pitch rates. Any dynamic motion involving a push off the ground (which is needed to get upright) triggers it. I reduced the weight to −0.5.air_time(weight +5.0): rewarded quadruped gait timing using all four feet. With front feet permanently airborne, the gradient it produced was misleading. I set the weight to 0.0.air_time_variance(weight −1.0): penalized asymmetric air time across feet. With front feet permanently airborne, the penalty was inescapable. I reduced the weight to −0.5.joint_pos(weight −0.7): penalized deviation from the default quadruped joint configuration, with an additional 5× multiplier during standing. The front shoulder and elbow joints must deviate substantially from defaults to keep the front feet elevated. I reduced the weight to limit the term’s influence.
The takeaway is general: a reward function designed for quadruped locomotion encodes implicit assumptions about posture that do not transfer to bipedal locomotion. I had to audit every term against the new target behavior.
Adding Safety: Height and Pitch-Over Penalties
To stop the optimizer from settling in the failure modes from earlier runs, I added two safety penalties. Their role is different from the shaping terms above: rather than nudging the policy toward better behavior, they exclude specific failure states from the reward landscape entirely.
- A fall-over penalty triggers when body pitch exceeds 90°, applying a large negative reward. Without it, the optimizer can briefly harvest pitch reward by tumbling through vertical.
- A body height penalty triggers when the base drops below 0.4 m. The height constraint prevents equilibria where Spot achieves the correct pitch angle from a collapsed or crouched position rather than a true standing one.
These two terms do not shape the gait; they define a feasibility boundary the policy must stay inside.
Building the Pitch Upright Reward
In parallel with the changes above, I had been working on a positive reward signal for the upright posture. My original concern was that the front feet penalty alone might cause Spot to avoid its front legs entirely by pitching forward into a faceplant rather than standing up. To provide a positive gradient toward the desired posture, I designed base_pitch_upright_reward: a piecewise function of body pitch angle θ that ramps from 0 to 1 between 0° and 50°, plateaus through 80°, then decays back to 0 and into a penalty beyond 90°. A height gate restricted the bonus to body heights between 0.5 m and 0.8 m to prevent exploits from crouched or tilted positions.
In the end, this reward was not needed. The safety penalties from the previous sub-section turned out to be strong enough on their own to eliminate the catastrophic failure modes the pitch reward was meant to prevent. Once those failure modes were closed off, the front feet penalty alone was sufficient to drive the policy toward the target posture. I removed the pitch reward and reverted to the simpler design.
Tuning Exploration to Escape Local Optima
Even with the safety terms in place, several runs converged to low-quality equilibria where Spot would stand briefly and then collapse without further improvement. To break out of these local optima, I increased two exploration parameters in PPO:
entropy_coeffrom 0.0025 to 0.005: the entropy bonus discourages premature convergence of the policy distribution.init_noise_stdfrom 1.0 to 2.0: the initial standard deviation of the Gaussian action distribution. Higher values produce more diverse early actions and raise the probability of discovering useful behaviors.
I applied these changes while warm-starting from the best checkpoint of the preceding run. Warm-starting preserved what the policy already knew about pushing upright, while the higher exploration gave it a better chance of discovering how to stay there and locomote.
Standing Behavior Emerges
With all the changes from the previous section in place, Spot finally began to stand and move on its hind legs. The reward function no longer penalized the upright posture, the front feet penalty was strong enough to drive consistent lift, and the safety penalties kept the optimizer out of the failure modes that had stalled earlier runs.
What 38,000 PPO Iterations Look Like
Figures 10–12 show the progression from the first sustained standing behavior through the final policy.



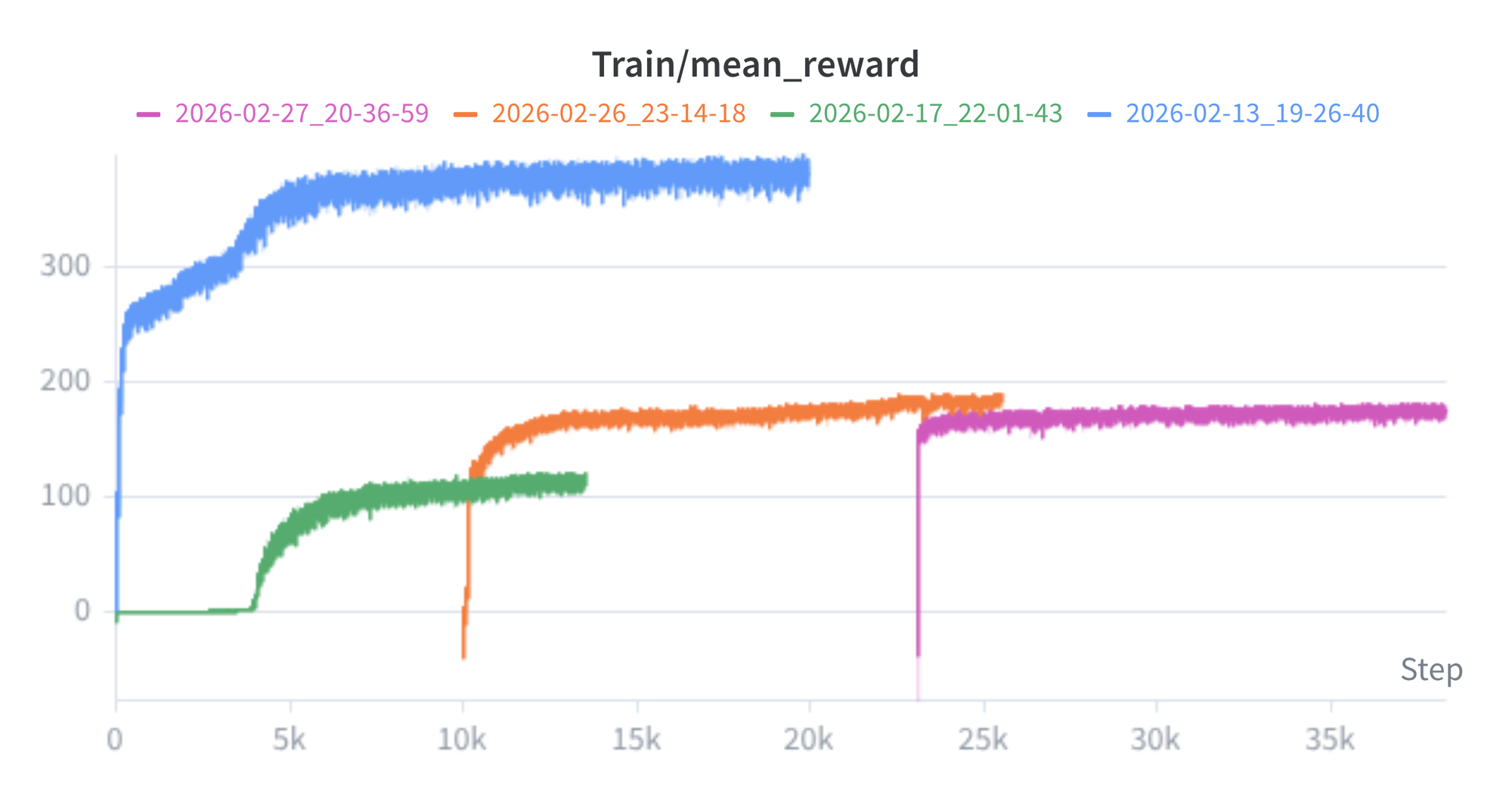
Four training runs produced the final policy:
- The initial quadruped baseline (~6,000 iterations).
- A first hind legs run (~5,000 iterations), introducing the front feet penalty and the standing-heavy command distribution.
- A second hind legs run (~23,000 iterations), where I dropped the standing fraction to 50% (
rel_standing_envs=0.5) and widened the velocity range to ±0.5 m/s lateral and ±0.2 rad/s yaw to start eliciting motion. - A final run (38,000 iterations), keeping 50% standing but widening the velocity range further to ±1.0 m/s lateral and ±0.5 rad/s yaw to encourage more aggressive bipedal locomotion.
Each run warm-started from the best checkpoint of the previous run.
Reading the Reward Curves
Figures 13 and 14 show the reward signals over the full training history.
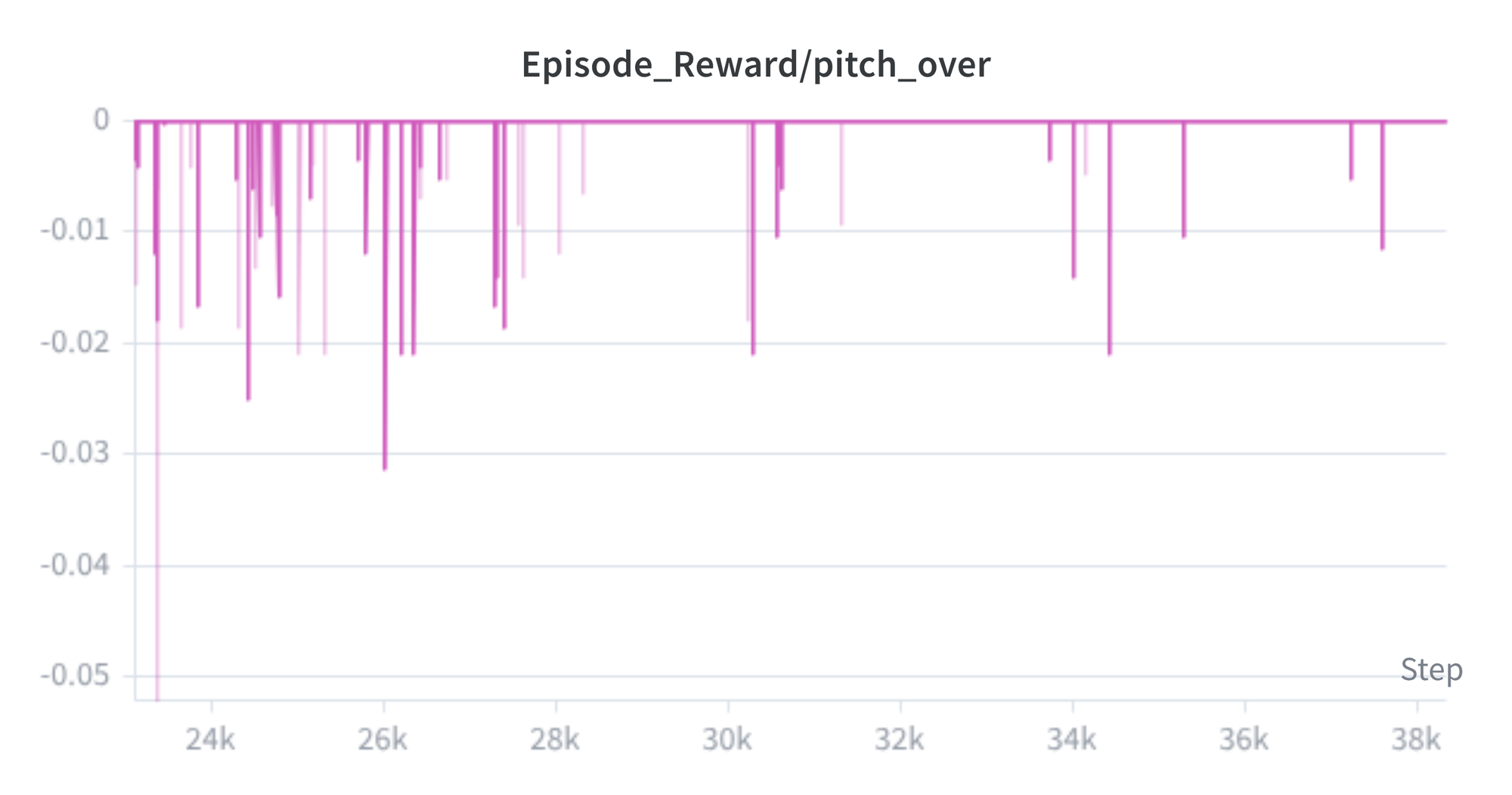
Two metrics are worth calling out. The front_feet_contact penalty started near −1.5 per step at the beginning of hind legs training and converged to roughly −0.16, meaning the policy keeps the front feet off the ground most of the time. The action_smoothness penalty improved from −0.9 to −0.45, reflecting smoother joint commands. The pitch-over graph in Figure 14 is the most informative: the negative spikes get less frequent and shallower over time, which means the policy is learning to stand more stably or recover from near-falls.
Deploying on the Real Spot
With training in simulation finished, the last step was to put the policy on real hardware. I loaded the 38,000-iteration checkpoint onto Spot and issued velocity commands from a PlayStation controller. Video 1 shows three consecutive trials. In each trial, Spot rises onto its hind legs and hops in the commanded direction, holding the upright posture throughout.
The real-world behavior was stable overall, with two small differences from simulation: the hind legs could not lift the robot quite as high, and Spot would occasionally touch down with its front legs before recovering. Neither difference limited the core behavior. The policy transferred zero-shot.
References
- NVIDIA Isaac Lab — GPU-accelerated robotics simulation framework used for training
- RSL-RL — PPO library from ETH Zürich’s Robotic Systems Lab for legged locomotion
- YouTube — Real-World Demo — Three deployment trials on physical Spot hardware