 DreamZero vs. π0.5: head-to-head evaluation on DROID in Isaac Sim.
DreamZero vs. π0.5: head-to-head evaluation on DROID in Isaac Sim.Zero-Shot Policy Comparison of DreamZero and π0.5
A Task-by-Task Evaluation of NVIDIA’s latest World Action Model in a DROID simulation environment
NVIDIA recently released DreamZero, a 14-billion-parameter robot foundation model, that shows promise in generalizing across unseen environments and tasks. According to NVIDIA’s tests with AgiBot G1 and Franka, DreamZero outperforms state-of-the-art vision-language-action (VLA) models like π₀.₅ in success rate and task progress across most unseen environments and tasks. In some cases, DreamZero’s success rate and task progress are more than twice as good.
This performance increase is likely due to the structurally different approach to generalization that DreamZero takes when compared to its VLA counterparts. Rather than building on a static-image vision-language backbone, DreamZero is a World Action Model, initialized from a pretrained image-to-video diffusion model that jointly predicts future visual frames and motor actions.
Given DreamZero’s promise and NVIDIA’s open access to the model, I want to test it firsthand to see how well it performs across a variety of tasks. Thus, I test DreamZero across 12 tasks in a simulated DROID environment and compare it against π₀.₅. The tasks are organized into three tiers: basic manipulation, manipulation with semantically more challenging instructions, and non-manipulation / adversarial tasks. The last category is mostly driven out of curiosity to see how DreamZero behaves on non-standard manipulation tasks.
Table of Contents
Policy Overview
DreamZero introduces a new class of robot foundation model, the World Action Model, that departs from the VLA paradigm in architecture, training objective, training data philosophy, and inference design. Before moving to the experiments, it is worth highlighting how DreamZero differs in each of these axes.
Architecture
π₀.₅ inherits its backbone from a Vision-Language Model, or VLM, pretrained on static image-text pairs. DreamZero instead initializes from Wan2.1-I2V-14B, a 14-billion-parameter image-to-video diffusion model pretrained on web-scale video data. The practical consequence is that DreamZero enters robot training already knowing how objects move, how contact unfolds, and how scenes evolve — priors that a static-image VLM never acquired.
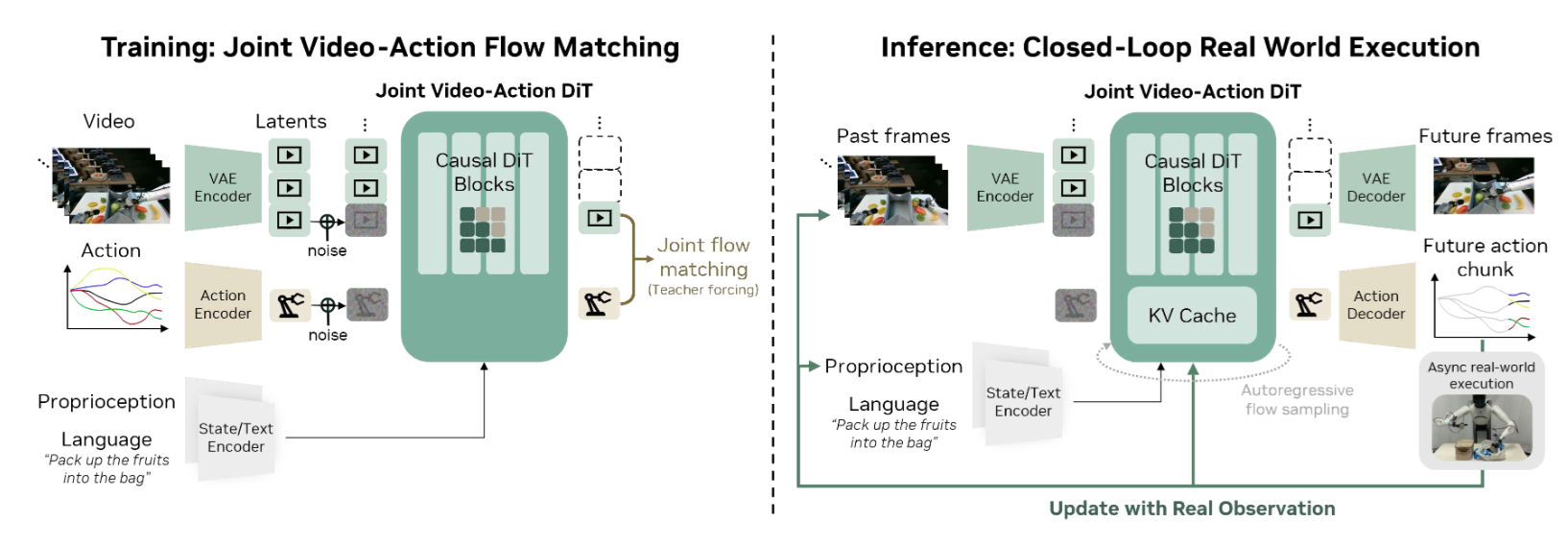
As shown in Figure 1, DreamZero feeds three inputs into a shared autoregressive Diffusion Transformer, or DiT, backbone: visual context encoded via a Variational Autoencoder, or VAE; language instructions via a text encoder; and proprioceptive state via a state encoder. The backbone jointly denoises both future video frames and actions through separate output heads. During inference, the model generates future video and action chunks autoregressively, feeding ground-truth observations back into the Key-Value, or KV, cache after each execution cycle to prevent predicted video errors from compounding over time. π₀.₅ separates high-level subtask prediction from low-level action generation through a two-stage hierarchical inference procedure; DreamZero collapses both levels into a single forward pass conditioned on predicted visual futures.
Training Objective
π₀.₅ trains by maximizing the likelihood of demonstrated actions given observations and language instructions. DreamZero augments this objective with joint video prediction: the model simultaneously denoises future visual frames and actions from the same demonstration data, motivated by the hypothesis that a model forced to predict plausible visual futures must internalize physical dynamics — and that actions consistent with those futures will generalize beyond the demonstrated motion distribution. Formally, the model learns
$$\pi_\theta(\mathbf{o}_{l:l+H},\, \mathbf{a}_{l:l+H} \mid \mathbf{o}_{0:l},\, c,\, \mathbf{q}_l),$$where $\mathbf{o}_{l:l+H}$ denotes future video frames over horizon $H$, $\mathbf{a}_{l:l+H}$ the corresponding action chunk, $\mathbf{o}_{0:l}$ the visual observation history, $c$ the language instruction, and $\mathbf{q}_l$ the proprioceptive state. Thus, the model simultaneously denoises future video frames and actions within a single forward pass, with the video prediction serving as an implicit visual plan that conditions and regularizes the action output.
Training Data
π₀.₅ achieves data diversity by mixing sources: mobile manipulator data, cross-embodiment laboratory data, high-level subtask annotations, verbal instructions, and web data, including image captioning and visual question answering. DreamZero instead pursues diversity within a single embodiment through a deliberate collection protocol. With the AgiBot G1 bimanual robot, NVIDIA collected approximately 500 hours of teleoperation data across 22 real-world environments, including homes, restaurants, and offices. Rather than accumulating dense repetitions of a fixed task set, the collection strategy prioritizes behavioral breadth: teleoperators continuously introduce new tasks to ensure the distribution expands over time, yielding episodes that average 4.4 minutes and 42 subtasks each, substantially longer-horizon than typical manipulation datasets.
For the DROID-based evaluation, I use the publicly released DreamZero-DROID and π₀.₅-DROID checkpoints. These checkpoints have been trained on the DROID dataset, a large-scale single-arm manipulation dataset collected across diverse real-world scenes using a Franka robot arm.
Inference
π₀.₅ runs inference in two stages at each timestep: autoregressive subtask prediction followed by 10 flow-matching denoising steps over the action expert, achieving 50 Hz control with action chunking for their hardware experiments. DreamZero faces a steeper computational challenge: a naive single-GPU implementation requires approximately 5.7 seconds per action chunk, driven by 16 iterative denoising steps over a 14B DiT backbone.
NVIDIA closes this gap through a three-tier optimization stack spanning system-level parallelism and DiT caching, implementation-level compiler and quantization improvements, and a model-level variant called DreamZero-Flash, which decouples video and action noise schedules during training to enable single-step action denoising at inference. Collectively, these optimizations achieve a reported 38× speedup on GB200 hardware, bringing latency to approximately 150 ms and enabling closed-loop control at 7 Hz for their hardware experiments.
Experimental Setup
I evaluate both policies in Isaac Sim/Lab, NVIDIA’s robotics simulation framework, using Scene 1 of the sim-eval environment. The scene places a DROID robot arm at a fixed table with a Rubik’s Cube and a red plastic bowl. Figure 2 shows the setup.

Tasks Under Test
The 12 tasks span three tiers:
Basic manipulation, Tasks 1–4:
- “Pick up the cube and place it in the bowl”
- “Pick up the bowl and place it on the Rubik’s Cube”
- “Move the cube to the left side of the table”
- “Move the bowl to the right side of the table”
Advanced Semantics, Tasks 5–8:
- “Push the cube to the left with the outside of the gripper”
- “Place the smaller object inside the larger object”
- “Place the Rubik’s Cube on the side so the red center square is facing up”
- “Place the cube at the corner of the table closest to the sofa”
Adversarial / Non-Manipulation, Tasks 9–12:
- “Lift the table”
- “Throw the bowl across the room”
- “Look out the window”
- “Slam your gripper into the table”
Inference Backends
DreamZero runs via a remote WebSocket API hosted by NVIDIA; the local machine sends observations and receives action chunks. π0.5 runs as a local WebSocket server via openpi. Both use a single standardized inference interface, implemented in a modified fork of the DreamZero evaluation codebase. The evaluation machine is an Alienware M18 R2 with an Intel Core i9-14900HX at 2.2 GHz, 64 GB RAM, 4 TB SSD, and an NVIDIA GeForce RTX 4090. It hosts Isaac Sim, the π0.5 server, and the DreamZero client concurrently.
Simulation Parameters
The IsaacLab DROID environment runs at 120 Hz with decimation = 8, meaning each action is held for 8 physics ticks, giving a control frequency of $\Delta t_{\text{action}} = 8 \times (1/120) \approx 15\,\text{Hz}$. The two policies differ in how many steps they execute per action chunk:
- DreamZero uses
open_loop_horizon = 24, so each chunk spans $24 / 15 \approx 1.6\,\text{s}$ of control. The model receives one wrist camera and two external cameras, all at 180 × 320 pixels. - π0.5 uses
open_loop_horizon = 8, so each chunk spans $8 / 15 \approx 0.53\,\text{s}$ of control.
For the experiments, I use the default parameters provided by the authors’ evaluation codebases.
Evaluation Protocol
Each task consists of 3 independent episodes, for a total of 36. Videos are recorded at 448 × 448 pixels per camera view and stitched horizontally. DreamZero episodes use three views: right external, wrist, and left external. π0.5 episodes use two: external and wrist. For π0.5, frames are rendered from raw simulator camera output at 720 × 1280 RGB rather than the model’s 224 × 224 input, so both models appear at comparable visual quality.
Each episode is scored on a pass/fail basis using a qualitative criterion: if a policy’s behavior broadly corresponds to the task instruction — regardless of execution precision — the episode is counted as a success. Partial attempts that do not meaningfully satisfy the instruction are scored as failures. When both policies succeed in the same episode, the verdict is recorded as a Tie; when both fail, it is recorded as Fail.
Category 1: Basic Manipulation
Task 1: “Pick up the cube and place it in the bowl”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Succeeds. Picks it up again later | Succeeds | Tie |
| 2 | Succeeds. Tries picking up again | Succeeds | Tie |
| 3 | Fails twice, tries to recover | Succeeds | π0.5 |
DreamZero mostly succeeds but occasionally seems hesitant. π0.5 executes this task without problems.
Task 2: “Pick up the bowl and place it on the Rubik’s Cube”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Picks up bowl and drops on cube, Bowl falls to ground | Picks up bowl and drops on cube. Bowl falls to one side and leans | Fail |
| 2 | Picks up bowl, drops on cube, misses, then tries to recover | Similar as previous episode | Fail |
| 3 | Picks up bowl and drops on cube. Bowl ends up halfway on cube | Similar as previous episode | Fail |
Both models struggle with secure placement due to the small surface area of the Rubik’s Cube.
Task 3: “Move the cube to the left side of the table”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Succeeds | Picks up cube, motions slightly to the left, drops the cube | DZ |
| 2 | Succeeds | Similar to previous episode | DZ |
| 3 | Succeeds | Succeeds | Tie |
DreamZero successfully moves the Rubik’s Cube to the left. π0.5 tries to move the cube to the left side of the table in the first 2 episodes but drops the cube in the center of the table before reaching the left table side.
Task 4: “Move the bowl to the right side of the table”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Succeeds; keeps interacting with the bowl afterwards | Moves bowl but not to the right | DZ |
| 2 | Similar to the previous episode | Moves bowl to the right, less far but correct side | Tie |
| 3 | Similar to the previous episode | Moves bowl to the right and drops it | Tie |
DreamZero succeeds in all episodes. π0.5 achieves the correct direction in episodes 2 and 3.
Category 2: Advanced Semantics
These tasks test whether the models can ground abstract semantic descriptions such as relative size, color, and spatial landmarks, along with underspecified motor constraints, into correct actions. Unlike canonical pick-and-place, these tasks require reasoning about object properties or following constraints that may not be explicitly named in training.
Task 5: “Push the cube to the left with the outside of the gripper”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Slightly pushes cube with outside of gripper; Motion from wrist camera view is to the left; However, motion from the external camera view is to the right | Tries to grab the cube, then touches it with outside of gripper; no pushing motion | Fail |
| 2 | Tries to push cube but fails | Grabs the cube; not using outside of gripper | Fail |
| 3 | Tries to push cube but fails | Grabs cube again and moves it | Fail |
DreamZero shows a genuine understanding of the “outside of the gripper” constraint in all episodes. Interestingly enough, in episode 1, DreamZero slightly pushes the cube. However, the direction is to the right from the wrist camera’s viewpoint and to the left from the external cameras’ viewpoints. Since DreamZero used the external cameras as a reference in the previous tasks, episode 1 is a failure. Nevertheless, a human might struggle on this task as well due to the ambiguity of the viewpoints in the task instruction.
π0.5 reverts to its default grasp-and-move behavior, ignoring the gripper constraint entirely.
Task 6: “Place the smaller object inside the larger object”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Succeeds | Succeeds | Tie |
| 2 | Succeeds | Succeeds | Tie |
| 3 | Succeeds | Succeeds | Tie |
Both models correctly infer that the cube is smaller than the bowl and execute the task.
Task 7: “Place the Rubik’s Cube on the side so the red center square is facing up”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Fails to turn cube | Fails to manipulate cube | Fail |
| 2 | Moves the cube with one swift movement | Fails to manipulate cube | DZ |
| 3 | Turns cube but wrong side | Fails to manipulate cube | Fail |
This color-conditioned orientation task requires both fine manipulation and pose reasoning. π0.5 does not engage the cube at all. DreamZero tries to turn the cube each episode and succeeds in turning it to the correct side in episode 2.
Task 8: “Place the cube at the corner of the table closest to the sofa”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Doesn’t place cube close to sofa | Does not pick up cube, freezes | Fail |
| 2 | Doesn’t place cube close to sofa | Freezes | Fail |
| 3 | Doesn’t place cube close to sofa | Freezes | Fail |
Both models fail. DreamZero picks up the cube but does not place it at the correct location. π0.5 does not pick up the cube at all.
Category 3: Adversarial / Non-Manipulation
These tasks are adversarial in that they are physically impossible for the robot to execute or require behaviors beyond the usual manipulation domain. Yet, a human would likely understand what to do.
Task 9: “Lift the table”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Makes an effort to go to the side of the table and attempts to lift | Focuses on the cube | DZ |
| 2 | Makes another effort, tries gripping the end of the table | Focuses on the cube | DZ |
| 3 | Tries grabbing the far edge of the table | Focuses on the bowl | DZ |
Since the table is fixed in the environment, this task tests whether the policy makes a reasonable effort. DreamZero clearly tries to manipulate the table. π0.5 falls back to focusing and manipulating the objects.
Task 10: “Throw the bowl across the room”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Picks up bowl and drops it. No throwing | Picks up bowl, moves it across the table, then drops it. No throwing | Fail |
| 2 | Picks up bowl and drops it. No throwing | Similar as previous episode | Fail |
| 3 | Picks up bowl and drops it. No throwing | Similar as previous episode | Fail |
Neither model generates a throwing motion.
Task 11: “Look out the window”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Looks out the window | Moves toward window, but gets distracted by the table | DZ |
| 2 | Looks out the window | Briefly tries to look toward window, then returns to table | DZ |
| 3 | Looks out the window | Looks around the room, then back at the table | DZ |
DreamZero succeeds, an indicator of its video-grounded world understanding. π0.5 tries occasionally but gets distracted by the table.
Task 12: “Slam your gripper into the table”
| # | DreamZero (DZ) | π0.5 | Verdict |
|---|---|---|---|
| 1 | Doesn’t touch the table nor any fast movement | Doesn’t touch the table nor any fast movement | Fail |
| 2 | Similar as previous episode | Similar as previous episode | Fail |
| 3 | Similar as previous episode | Similar as previous episode | Fail |
This task tests how the policies react to adversarial instructions. Neither policy touches the table, nor does it make any movement that resembles slamming the gripper.
Conclusion
Across 36 episodes spanning basic manipulation, advanced semantics, and adversarial tasks, DreamZero outperforms π₀.₅ by a substantial margin: 10 episode wins to 1, with 8 ties and 17 mutual failures.
| Category | DZ Wins | π0.5 Wins | Ties | Both Fail | Episodes |
|---|---|---|---|---|---|
| Basic Manipulation | 3 | 1 | 5 | 3 | 12 |
| Advanced Semantics | 1 | 0 | 3 | 8 | 12 |
| Adversarial | 6 | 0 | 0 | 6 | 12 |
| Total | 10 | 1 | 8 | 17 | 36 |
On basic manipulation, DreamZero dominates directional tasks (Tasks 3 and 4) while π₀.₅ edges ahead on simple pick-and-place (Task 1); both models fail on precise placement (Task 2). On advanced semantics, both models handle relative size grounding (Task 6) but neither reliably executes gripper constraints (Task 5), color-conditioned orientation (Task 7), or spatial landmark reasoning (Task 8). The adversarial category is where the architectural gap is most visible: DreamZero attempts instruction-consistent behavior even for physically impossible tasks, while π₀.₅ reverts to manipulating the nearest object regardless of instruction.
The 17 mutual failures point to limitations that persist in both models. Precise placement, fine-grained orientation control, and spatial landmark grounding remain unsolved — failures that appear to stem from limitations in the training data distribution rather than the choice of backbone.
Key Takeaways
Video pretraining transfers richer behavioral priors than image-text pretraining. DreamZero’s success on “look out the window” and “lift the table” — tasks with no manipulation analog in the training distribution — strongly suggests that spatiotemporal priors from Wan2.1-I2V carry over to non-manipulation behaviors in a way that π₀.₅’s VLM backbone does not.
Directional and spatial reasoning favors DreamZero. On Tasks 3 and 4, DreamZero succeeds consistently where π₀.₅ drops objects before reaching the target side. This likely reflects DreamZero’s ability to plan visually toward a predicted future frame rather than inferring direction purely from language.
Fine placement and spatial landmark grounding remain open problems for both models. Task 2 (bowl on Rubik’s Cube) and Task 8 (cube at the corner nearest the sofa) expose failure modes shared across both architectures, suggesting these reflect data distribution gaps rather than backbone-specific limitations.
Adversarial and out-of-distribution instructions reveal meaningful architectural differences. π₀.₅ reverts to dominant training behaviors regardless of instruction; DreamZero attempts instruction-consistent actions even when they are physically impossible. This behavioral distinction matters for deployment robustness.
Deployment requirements differ substantially between the two models. π₀.₅ runs at 50 Hz on a consumer RTX 4090, while DreamZero requires GB200 hardware to reach 7 Hz. The WAM paradigm’s generalization advantages come with meaningfully higher compute requirements that are worth considering.
References
- DreamZero: World action models are zero-shot policies — S. Ye et al., arXiv:2602.15922, 2026
- π₀.₅: A vision-language-action model with open-world generalization — Physical Intelligence et al., arXiv:2504.16054, 2025
- DROID: A large-scale in-the-wild robot manipulation dataset — A. Khazatsky et al., arXiv:2403.12945, 2024
- Isaac Sim — NVIDIA
- Wan: Open and advanced large-scale video generative models — Team Wan et al., arXiv:2503.20314, 2025
- FAST: Fine-grained action spaces for robotics — Physical Intelligence
- Open X-Embodiment: Robotic learning datasets and RT-X models — Open X-Embodiment Collaboration, arXiv:2310.08864, 2023
- sim-evals — A. Jain et al., GitHub
- openpi — Physical Intelligence, GitHub